Investigating Symbiosis in Robotic Ecosystems (ICRAS 2025)
Post's content provided by: Xuezhi
Authors: Xuezhi Niu, Didem Gürdür Broo
Modern robot teams need reliable coordination under partial observability and differing capabilities. We study a core
question: can structure inter-agent rewards improve cooperation in heterogeneous multi-robot systems?
We model interactions via a symbiosis lens (mutualism, commensalism, parasitism) and encode partner
impact directly into each agent’s reward.
Introduction
Formally, for agent \(i\) we use: $$ R_i = \alpha P_i + \beta \sum_{j \neq i} \Delta P(a_i, a_j),$$ where \(P_i\) is task performance for \(i\) and \(\Delta P(a_i, a_j)\) measures the marginal effect of \(i\)’s action on partner \(j\). This keeps local learning objectives while shaping behavior toward cooperative equilibrium. We integrate this reward into standard policy-gradient MARL (e.g., MAPPO variants) with minimal overhead and evaluate on high-dimensional manipulation (ShadowHand object passing) and mobile manipulation. The result is more stable training and lower variance than plain rewards.
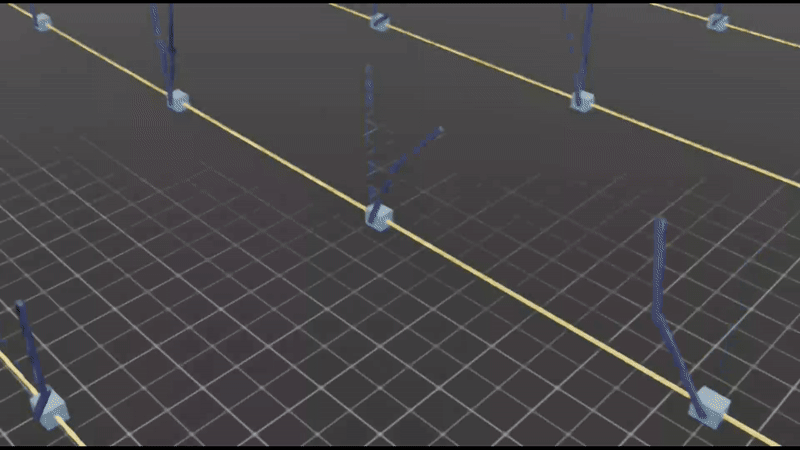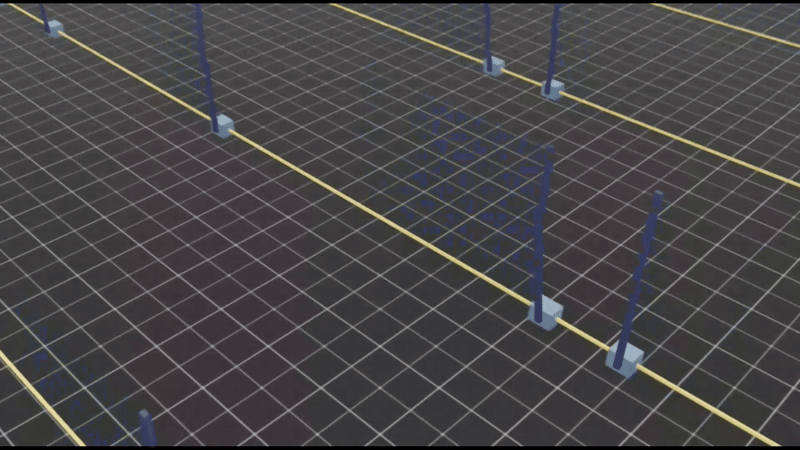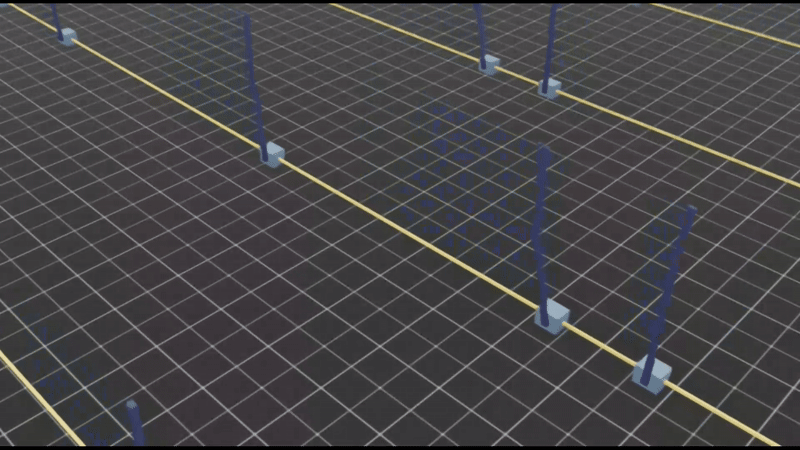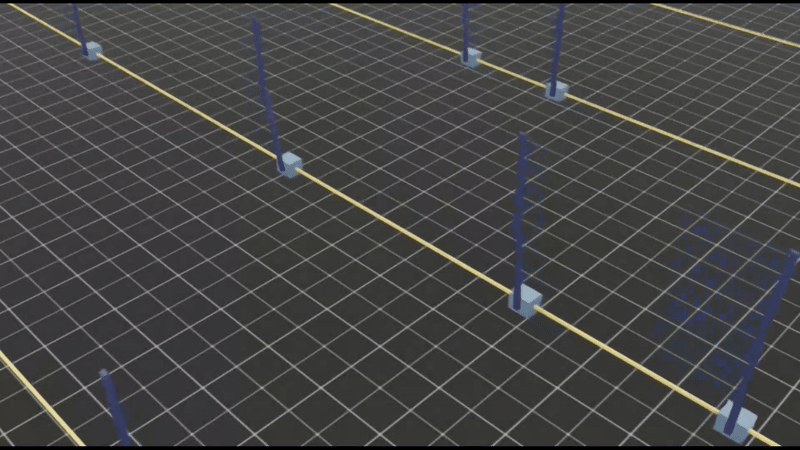
CartPendulum
Cooperative Balancing: Multiple agents control different aspects of the double cart-pendulum system, requiring coordinated actions to maintain balance.

ShadowHand
Shadow Hand Object Passing: Multiple agents controlling different finger groups of the dexterous hand, collaborating through shared rewards to manipulate and pass objects with precision.

MobileFranka
Mobile Manipulation: Combining base movement and arm control agents that benefit from shared reward signals to perform coordinated navigation and manipulation tasks.
Symbiotic Reward Modeling
A key difficulty in multi-agent learning is the explosion of joint behaviors that look promising in isolation but conflict
at execution time. Our reward couples agents via \(\Delta P\), which penalizes harmful interference and reinforces
complementary behaviors.
Let \(H = { a_1, \dots, a_n }\) denote a set of heterogeneous robots, where each \(a_i\) has a capability set \(C_i\),
resource vector \(D_i\), and performance function \(P_i\). The interaction between \(a_i\) and \(a_j\) is given by
\(I(a_i, a_j)\), representing performance change due to cooperation. A symbiotic pair satisfies \(I(a_i, a_j) >
\max\{P_i, P_j\} - \delta,\) where \(\delta \geq 0\) accounts for noise. Performance deltas \(\Delta P(a_i, a_j)\)
classify relationships:
- Mutualism: \(\Delta P(a_i, a_j) > 0\) and \(\Delta P(a_j, a_i) > 0\)
- Commensalism: \(\Delta P(a_i, a_j) > 0\) , \(\Delta P(a_j, a_i) = 0\)
- Parasitism: \(\Delta P(a_i, a_j) > 0\) , \(\Delta P(a_j, a_i) < 0\)
Total system performance for a subset \(S \subseteq H\) is: $$ P_{\text{total}}(S) = \sum_{a_i \in S} P_i + \sum_{(a_i, a_j) \in E(S)} I(a_i, a_j). $$ We embed the reward in a MAPPO-style pipeline and compare against strong PPO-family baselines without symbiosis terms. When optimality certificates are not required, we emphasize robust convergence and near-optimal performance under realistic noise, contact dynamics, and partial observability.
Highlights: The symbiosis variant reaches target success more consistently and with fewer catastrophic drops during training; bounded-suboptimal tuning (clip, entropy) remains compatible. Across long runs, the symbiosis reward improves success rates on difficult seeds and reduces outcome spread; it also shortens recovery after rare failures.
Citation
If you find the idea useful, please consider citing our work:
@inproceedings{niu2025symbiosis,
title={Investigating Symbiosis in Robotic Ecosystems: A Case Study for Multi-Robot Reinforcement Learning Reward Shaping},
author = {Xuezhi Niu and Didem Gürdür Broo},
booktitle = {the 2025 9th International Conference on Robotics and Automation Sciences (ICRAS)},
year = {2025},
publisher = {IEEE}
}
Event Gallery

